I originally sent this to the ANTLR interest group, but figured it would make for a decent post here as well.
I’ll start with a couple fundamental concepts. First, there are three key things that get parsed in an IDE:
- The syntax highlighter lexes the current document.
- Files that are not opened in the editor.
- Files that are open (for editing) in the editor.
Second, the very nature of writing code results in semantically incorrect (invalid) code *almost always*, and syntactically incorrect code most of the time. Very often, the code is in a state that it can’t even be lexed by the language’s lexer. It is critical for each of the above cases to absolutely minimize the impact on the ability to provide meaningful coding assistance. This point is the fundamental reason I believe incremental lexers and parsers are significantly less valuable to an IDE than is often believed.
Here are several things to remember about each of the three "parsables".
Syntax Highlighting
Syntax highlighting is the only item above that requires a real-time component. The syntax highlighter must be able to perform a standard view update in less than 20ms for any character input. The easiest way to accomplish this is writing a "lightweight" lexer that, given any input that starts at a token boundary can tokenize the remaining text. The backing engine for my current syntax highlighters maintains a list of lines that do not start with a token boundary – for many languages this occurs for the 2nd and following lines of a multi-line comment. I can start lexing at any line in the entire document as long as it isn’t contained in this list, and can stop under a similar condition (the stop condition is slightly more complicated so I’ll leave it out). *The primary syntax highlighter must not perform any form of semantic analysis of the result.* A secondary highlighting component can asynchronously add highlighting to semantic elements such as semantic definitions, references, or other names.
Here are some basic things I do to improve the performance of the syntax highlighter’s lexer:
- Do not lex language keywords that look like an identifier. Instead, when I assign colors to tokens I check if the identifier is in a hashtable of language keywords.
- Do not restrict escape sequences in strings literals to be valid. The only escape to handle is \" to not close the string. If strings cannot span multiple lines in your language, then treat an unclosed string literal as ending at the end of the current line.
- If character literals start and end with, say, an apostrophe (‘) and no other literal in the language uses an apostrophe, then treat character literals like you treat strings (allow any number of characters inside them, and make sure to stop the token at the end of a line if it’s missing a closing apostrophe.
- Make sure the lexer is strictly LL(1).
- Include the following rule at the end of the grammar: ANY_CHAR : . {Skip();};
Unopened Files In The Project
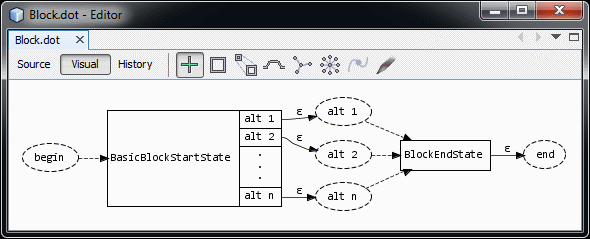
For any block of language code that does not affect other open documents (such as the body of functions in C), don’t validate the contents of a block. For C, this could mean parsing the body of a method as:
body:block
block:'{' (~('{'|'}') | block)* '}';
Often, all you care about are the declarations and definition headers. This sort of "loose" parsing prevents most syntax errors in the body of methods from impacting the availability of the key information – references to the declarations are usable at other points in code. Further improvements can be made by forcing a block termination when a keyword is found that cannot appear in the block, but since this can cause some unexpected results and offers relatively low "bang for the buck", I recommend holding off on this approach.
Files Open For Editing
One of the most difficult aspects of an "intelligent" IDE is how to handle files while they are being edited. In designing an appropriate attack on the problem, it’s important to identify the types of information you can gather and for each: 1) Categorize it, 2) Give it a difficulty rating, 3) What can you do with it, and 4) Prioritize it. I’ll give several examples along with how you might leverage each to improve the overall usefulness of the IDE. Note that all of the below are performed asynchronously using a parameterized deferred action strategy described in a section below.
Information: Invalid literals (strings, numbers, or characters)
- Category: Lexical errors
- Difficulty: Given access to the tokens in the current document, very easy. Incremental by nature due to intentionally implementing it using the syntax highlighter’s lexer and strategy.
- Action: Underline the token or part of a token that is invalid.
- Priority: Useful information that is easy and computationally inexpensive to maintain. This might be implemented at a very early stage when, say, learning how to asynchronously "mark" text after it has been highlighted (information that is helpful for a number of more difficult features later).
Information: Language element blocks (perhaps method and field declarations, but not locals).
- Category: Editor navigation
- Difficulty: Easy to "first-pass" it by running the unopened files parser. For a high-quality product, you’ll use a different strategy that I’ll describe under the Advanced Strategies section below.
- Action: Populate the "type and member dropdown bars" and the top of the editor, update a pane that shows a structural outline of the current file, and mark large blocks (say full methods) as collapsible.
- Priority: This is a fundamental and relatively easy feature that should be implemented in some form soon after syntax highlighting is in place.
Information: Argument type mismatch
- Category: Language compile-time semantics
- Difficulty: Requires full type information for the target method and semantic details of the expression(s) passed as arguments. If you just use the language’s compiler for this information, the information will only be available when the compiler can get far enough to observe the problem. If you don’t have access to the compiler’s code, you might also be unable to turn off several compiler features that slow down the operation significantly.
- Action: Underline the parameter(s) or the call with a tooltip or other description of the problem.
- Priority: While quite useful in a statically-typed language, this is an extremely difficult feature to fully implement and is therefore relatively low on the priority list.
Auto-completion
I decided to address this separately from the above. Here are the governing factors an auto-complete feature:
- It must be fast (sub-50ms *latency*) – the user is actively waiting for the results.
- The document is never syntactically correct when this feature is used.
Core strategy: This is not complete, but gives a general idea of the initial approach that gives quite tolerable results.
Start at the cursor and read tokens in reverse "until they no longer affect the current location". For c-like languages, this means reading identifiers, periods, arrows (->), and parenthesis with arbitrary contents and nesting.
The result can generally be parsed as a postfix expression; the parser should be able to built an AST for just that postfix expression without any additional context.
Evaluate the AST against its previously cached context – use the buffer-mapped span of the enclosing language elements to evaluate the visibility of elements as you manually walk the expression’s AST. At each step, generate a list of visible elements, and select the appropriate item before continuing. At the end, you’ll have a list of accessible items at the point auto-complete was triggered – match that against any text the user has already typed and either fill in the single result or present a dropdown.
Advanced Parsing
(only one example here so far)
Robust and fast language element identification in the presence of errors:
Due to the way the unopened file parser skips parsing function bodies, it tends to be extremely fast. When it fails to parse a document, due to say a syntactically incorrect field declaration, you don’t want your opened files to stop showing navigation information. Upon failure, the opened file strategy can fall back to using an ANTLR fragment parser to locate the headers of language elements (class, field, or function definitions), from that information you can infer the scope of each element, and generally identify most or all of the items declared in a document.
After identifying elements by name and their "span" in the document, you’ll want to keep a list of the information around in case future edits render both of the above parsing methods unusable. When the header portion of a language element is deleted as part of a document edit, the element can be immediately removed from the cached list of elements located in the current file. Further, if the previous element had an inferred termination due to mismatched braces, its span can immediately be expanded to include any remaining portion of the original span of the removed language element. The cache relies on [buffer span mapping] to properly track the current location of each language element as edits are applied to the document.
Any time the IDE tries to offer information about a language element in an opened file, the information is checked against that documents cache for potential updates (for example, Go To Definition should always go to the correct location, even if a large block of text was pasted above the definition).
Deferrable Action Strategy
This strategy is basically a modified, asynchronous "dirty" flag based trigger for an arbitrary action. The strategy addresses several goals:
- Since the operation is not "free", you don’t want to repeat it too many times.
- Since the operation takes more time than the actions that necessitate the action (typing keystrokes takes less time than a re-parse), you want to A) run the action on a different thread and B) try to avoid running the action on old data.
Here’s the basic implementation:
- When the action’s target is initially marked dirty, a timer is set so the clean-up action will run on a separate thread after some period of time.
- When some operation occurs that *would* mark the target dirty, except the target is already dirty, the timer is deferred – reset to occur at a later time.
- Decide on a "cancellation policy":
- When the action runs, does it mark the target clean for the state before running or the state after running? If it marks the target clean *after* running, then you can simply ignore a request to mark it dirty while running (this is the rare case though).
- Are the results useful if the target is marked dirty after the action starts but before it finishes? If not, you want to cancel any currently running operation and go back to step 1 (or 2). If so, keep going and go to step 1 after it completes and mark the target dirty (and reset the timer). Normally this is a gray area – the results are partially useful so the decision is balanced in some manner between the speed of the operation, the rate at which things are marking the target dirty, and the usefulness of "stale" results (results that are available only after the target was marked dirty again).